High-Performance Virtualization: SR-IOV and Amazon's C3 Instances
Amazon recently announced their next-generation cluster compute instances dubbed C3" which feature newer Ivy Bridge Xeons with higher clock rates, about the same amount of RAM, and 16 physical cores (32 threads). In addition to the incremental step up in the CPU though, these C3 instances now come with an "Enhanced Networking" feature which, at the surface, sounds like it might provide a significant performance boost for EC2 clusters running tightly coupled parallel jobs.
As it turns out, this "Enhanced Networking" is actually SR-IOV under the hood, and I just happened to have spent a fair amount of time testing SR-IOV performance in the context of architecting Comet, SDSC's upcoming supercomputer which will be using SR-IOV to provide high-performance virtualized InfiniBand. In fact, I was to present some of the work my colleagues and I did in evaluating SR-IOV InfiniBand performance at SC'13 just a few days after Amazon announced these C3 instances, and as a result, I already had a leg up on understanding the technology underpinning these new higher-performance compute instances.
Since Amazon has officially made SR-IOV the real deal in terms of selling it in their new high-end virtual compute instance and I've already got performance data for how well SR-IOV performs with InfiniBand, I figure I'd give these new C3 instances a spin and revisit the old topic of comparing the performance of EC2 Cluster Compute instances to high-performance interconnects. To keep things fresh though, I also thought it might be fun to see how Amazon's new SR-IOV'ed 10gig compares to SDSC's SR-IOV'ed QDR InfiniBand in a showdown of both virtualization approaches and interconnect performance.
Before getting into the performance data though, it might be useful to describe exactly what SR-IOV is and how it provides the significant performance boost to VMs that it does. If you're just interested in the bottom line, feel free to skip down to the benchmark data.
When virtualization enters the picture, though, DMA isn't so simple because the memory address space within the VM (and, by extension, the address to which the DMA operation should write) is not the same as the underlying host's real memory address space. Thus, while a VM can trigger a DMA operation, the VM's hypervisor needs to intercept that DMA and translate the operation's memory address from the VM's address space to the host's. As a result, DMAs originating within a VM still wind up interrupting the host CPU so that the hypervisor can perform this address translation. The situation gets worse if the I/O operation is coming from a network adapter or HCA, because if multiple VMs are running on the same host, the hypervisor must then also act as a virtual network switch:
In the above schematic, the data (red arrows) comes into the host InfiniBand adapter (hereafter referred to as the HCA, the green block), and the HCA's physical PCIe function (the logical representation of the HCA on the PCIe bus) transmits that incoming data over the PCIe bus. It is then up to the hypervisor (and its device driver for the HCA) to perform both address translation and virtual switching to ensure that the data coming from the HCA gets placed in the correct memory address belonging to the correct VM. As one might expect, the more time the data needs to bounce around in the blue hypervisor layer, the higher and higher the latency will be for the I/O operation.
The actual act of translating memory addresses from the physical host's memory address space to the address space of a single VM is logically very simple, so it's easy to imagine that some sort of dedicated hardware could be added that provides a simple address translation service (ATS**) between the host and VM memory addresses:
Because this virtual ATS provider only needs to do simple table lookups to map physical addresses to VM addresses, using it should be significantly quicker than having to interrupt the host CPU and force the hypervisor to provide the address translation. Thus, a DMA operation coming from the PCIe bus can go to the virtual ATS provider, spend only a brief time there getting its new virtual address, and then completely bypass the hypervisor and write straight to the VM's memory.
Of course, this idea is such a good one that all of the major CPU vendors have incorporated this dedicated virtual ATS into their chipset's I/O memory management units (IOMMU) and call the feature things like "VT-d" (in Intel processors) and "AMD-Vi" (in AMD processors). VT-d is what allows hosts to provide PCIe passthrough to VMs by acting as the glue between an I/O device on the PCIe bus and the VM's memory address space.
Unfortunately, the logic provided by VT-d and the IOMMU is too simple do anything like virtual switching, which is necessary to allow multiple VMs to efficiently share a single I/O device like an HCA. The HCA thinks it's just interacting with a single host, and significant logic is required by the hypervisor to make sure that the I/O operations requested by each VM are coalesced as efficiently as possible before they make it to the HCA to reduce excessive, latency-inducing interrupts on the HCA.
Rather than try to come up with a way to provide dedicated hardware that does virtual switching for VMs, the smart folks in the PCI-SIG decided to sidestep the problem entirely and instead create a standard way for a single physical I/O device to present itself to the IOMMU (or more precisely, the PCIe bus) as multiple virtual devices. This way, the logic for coalescing I/O operations can reside in the I/O device itself, and the IOMMU (and the VMs behind it) can think they are interacting with multiple separate devices, each one behaving as if it was being PCIe-passthrough'ed to a VM.
This is exactly what SR-IOV is--a standardized way for a single I/O device to present itself as multiple separate devices. These virtual devices, called virtual PCIe functions (or just virtual functions), are lightweight versions of the true physical PCIe function in that, under the hood, most of the I/O device's functionality shares the same hardware. However, each virtual function has its own
** I am being very sloppy with my nomenclature here, and be aware that parts of this explanation have been significantly simplified to illustrate the problem and the solution. Strictly speaking, ATS is actually another open standard which complements SR-IOV and provides a uniform interface for the virtual IOMMU features present in VT-d. Thus, ATS is a subset of VT-d. If you're really interested in the details, you really should be reading literature provided by PCI-SIG and its constituent vendors, not me. I don't know what I'm talking about.
To test the benefits of SR-IOV on Amazon, I ran a four-node cluster of c3.8xlarge instances with SR-IOV enabled. Since the whole motivation for all of this is in using SR-IOV for virtualized HPC, all of the tests I ran on this cluster used MPI, and this first round of data I'm posting will detail the lower-level performance of message passing over 10gig virtualized with SR-IOV.
In addition to this four-node SR-IOV'ed EC2 cluster, I ran all of my benchmarks on two additional four-node cluster configurations for comparison:
The error bars in the above diagram represent 3σ in the average of average latencies (statisticians, cover your ears), so roughly 95% of latencies encountered when passing these messages fall within the shown ranges. For these smaller messages, SR-IOV provides 3× to 4× less variation in latency. As the message size gets larger though, the variation begins to widen as the ugly features of both TCP/IP and Ethernet begin to emerge: congestion forces data retransmission, which has a deleterious effect on observed latency.

As it turns out, this "Enhanced Networking" is actually SR-IOV under the hood, and I just happened to have spent a fair amount of time testing SR-IOV performance in the context of architecting Comet, SDSC's upcoming supercomputer which will be using SR-IOV to provide high-performance virtualized InfiniBand. In fact, I was to present some of the work my colleagues and I did in evaluating SR-IOV InfiniBand performance at SC'13 just a few days after Amazon announced these C3 instances, and as a result, I already had a leg up on understanding the technology underpinning these new higher-performance compute instances.
Since Amazon has officially made SR-IOV the real deal in terms of selling it in their new high-end virtual compute instance and I've already got performance data for how well SR-IOV performs with InfiniBand, I figure I'd give these new C3 instances a spin and revisit the old topic of comparing the performance of EC2 Cluster Compute instances to high-performance interconnects. To keep things fresh though, I also thought it might be fun to see how Amazon's new SR-IOV'ed 10gig compares to SDSC's SR-IOV'ed QDR InfiniBand in a showdown of both virtualization approaches and interconnect performance.
Before getting into the performance data though, it might be useful to describe exactly what SR-IOV is and how it provides the significant performance boost to VMs that it does. If you're just interested in the bottom line, feel free to skip down to the benchmark data.
Virtualizing I/O and SR-IOV
The I/O performance of virtual machines has long suffered because I/O performance is largely the result of I/O devices' ability to perform DMA--direct memory access--whereby the I/O device can write directly to the compute host's memory without having to interrupt the host CPU. Not having to interrupt the CPU means that I/O operations can bypass the thousands (or tens of thousands) of cycles that the host OS's I/O stack may impose for the operation, and as a result, be performed with very low latency.When virtualization enters the picture, though, DMA isn't so simple because the memory address space within the VM (and, by extension, the address to which the DMA operation should write) is not the same as the underlying host's real memory address space. Thus, while a VM can trigger a DMA operation, the VM's hypervisor needs to intercept that DMA and translate the operation's memory address from the VM's address space to the host's. As a result, DMAs originating within a VM still wind up interrupting the host CPU so that the hypervisor can perform this address translation. The situation gets worse if the I/O operation is coming from a network adapter or HCA, because if multiple VMs are running on the same host, the hypervisor must then also act as a virtual network switch:
 |
| Data Path in Virtualized I/O |
In the above schematic, the data (red arrows) comes into the host InfiniBand adapter (hereafter referred to as the HCA, the green block), and the HCA's physical PCIe function (the logical representation of the HCA on the PCIe bus) transmits that incoming data over the PCIe bus. It is then up to the hypervisor (and its device driver for the HCA) to perform both address translation and virtual switching to ensure that the data coming from the HCA gets placed in the correct memory address belonging to the correct VM. As one might expect, the more time the data needs to bounce around in the blue hypervisor layer, the higher and higher the latency will be for the I/O operation.
The actual act of translating memory addresses from the physical host's memory address space to the address space of a single VM is logically very simple, so it's easy to imagine that some sort of dedicated hardware could be added that provides a simple address translation service (ATS**) between the host and VM memory addresses:
 |
| Data Path for Virtualized I/O with Address Translation in Hardware |
Because this virtual ATS provider only needs to do simple table lookups to map physical addresses to VM addresses, using it should be significantly quicker than having to interrupt the host CPU and force the hypervisor to provide the address translation. Thus, a DMA operation coming from the PCIe bus can go to the virtual ATS provider, spend only a brief time there getting its new virtual address, and then completely bypass the hypervisor and write straight to the VM's memory.
Of course, this idea is such a good one that all of the major CPU vendors have incorporated this dedicated virtual ATS into their chipset's I/O memory management units (IOMMU) and call the feature things like "VT-d" (in Intel processors) and "AMD-Vi" (in AMD processors). VT-d is what allows hosts to provide PCIe passthrough to VMs by acting as the glue between an I/O device on the PCIe bus and the VM's memory address space.
Unfortunately, the logic provided by VT-d and the IOMMU is too simple do anything like virtual switching, which is necessary to allow multiple VMs to efficiently share a single I/O device like an HCA. The HCA thinks it's just interacting with a single host, and significant logic is required by the hypervisor to make sure that the I/O operations requested by each VM are coalesced as efficiently as possible before they make it to the HCA to reduce excessive, latency-inducing interrupts on the HCA.
Rather than try to come up with a way to provide dedicated hardware that does virtual switching for VMs, the smart folks in the PCI-SIG decided to sidestep the problem entirely and instead create a standard way for a single physical I/O device to present itself to the IOMMU (or more precisely, the PCIe bus) as multiple virtual devices. This way, the logic for coalescing I/O operations can reside in the I/O device itself, and the IOMMU (and the VMs behind it) can think they are interacting with multiple separate devices, each one behaving as if it was being PCIe-passthrough'ed to a VM.
This is exactly what SR-IOV is--a standardized way for a single I/O device to present itself as multiple separate devices. These virtual devices, called virtual PCIe functions (or just virtual functions), are lightweight versions of the true physical PCIe function in that, under the hood, most of the I/O device's functionality shares the same hardware. However, each virtual function has its own
- PCIe route ID - thus, it really appears as a unique PCIe function on the bus
- Configuration space, base address registers, and memory space
- Send/receive queues (or work queues), complete with their own interrupts
These features allow the virtual functions to be interrupted independently of each other and process their own DMAs:
 |
| Data Path for Virtualized I/O with SR-IOV |
And, of course, the I/O device still has its fully featured physical function that can interact with the hypervisor. The actual logic that figures out how these virtual functions share the underlying physical hardware on the I/O device is not prescribed by the SR-IOV standard, so hardware vendors can optimize this in whatever way works best. In the above SR-IOV schematic, this logic is labeled as the "sorter."
There's a lot more interesting stuff to be said about SR-IOV, but this discussion has proven to be a lot more technical and acronym-laden than I initially set out. Let it suffice to say that SR-IOV is what allows a 10gig NIC or InfiniBand HCA to present itself as multiple separate I/O devices (virtual functions), and these virtual functions can all interact with VT-d independently. This, in turn, allows all VMs to bypass the hypervisor entirely when performing DMA operations.
** I am being very sloppy with my nomenclature here, and be aware that parts of this explanation have been significantly simplified to illustrate the problem and the solution. Strictly speaking, ATS is actually another open standard which complements SR-IOV and provides a uniform interface for the virtual IOMMU features present in VT-d. Thus, ATS is a subset of VT-d. If you're really interested in the details, you really should be reading literature provided by PCI-SIG and its constituent vendors, not me. I don't know what I'm talking about.
Performance of SR-IOV'ed 10gig on Amazon
With that explanation out of the way, now we can get down to what matters: does SR-IOV actually do what it's supposed to and increase the performance of applications that are sensitive to network performance?To test the benefits of SR-IOV on Amazon, I ran a four-node cluster of c3.8xlarge instances with SR-IOV enabled. Since the whole motivation for all of this is in using SR-IOV for virtualized HPC, all of the tests I ran on this cluster used MPI, and this first round of data I'm posting will detail the lower-level performance of message passing over 10gig virtualized with SR-IOV.
In addition to this four-node SR-IOV'ed EC2 cluster, I ran all of my benchmarks on two additional four-node cluster configurations for comparison:
- A cluster of c3.8xlarge instances on EC2 without SR-IOV enabled. As it turns out, SR-IOV is disabled by default on C3 instances, which means you can run any C3 instance with the old-style virtualized I/O. Comparing the SR-IOV performance to this cluster would isolate the performance improvement of SR-IOV over non-SR-IOV virtualization.
- A native (non-virtualized) cluster with a 10gig interconnect. Comparing SR-IOV performance to this cluster would reveal the performance loss from using the best available commercial cloud offering for high-performance virtualized compute.
Latency
As previously detailed, SR-IOV provides a mechanism for hypervisor-bypass which should reduce the latency associated with I/O. So, let's look at the latency of passing MPI messages around:
 |
| MPI latency. Note the log/log scale. |
Just as we'd expect, SR-IOV provides a significant decrease in the latency of message passing over the 10gig interconnect. For small messages (< 1K), SR-IOV provides 40% less latency which is a substantial improvement over the previous cc2 instances. For larger messages, the bandwidth begins to dominate overall throughput and the relative improvement is not as great. However, even at the largest messages sizes tested (4 megabytes), SR-IOV delivered a minimum of 12% improvement in latency in these tests.
Also quite impressively, the jitter in small-message latency is significantly reduced by SR-IOV, presumably because the I/O latency is no longer affected by whatever noise exists in the hypervisor:
 |
| MPI latency with error bars representing 3σ of averages. Note the semilog scale, which differs from the previous latency graph. |
The error bars in the above diagram represent 3σ in the average of average latencies (statisticians, cover your ears), so roughly 95% of latencies encountered when passing these messages fall within the shown ranges. For these smaller messages, SR-IOV provides 3× to 4× less variation in latency. As the message size gets larger though, the variation begins to widen as the ugly features of both TCP/IP and Ethernet begin to emerge: congestion forces data retransmission, which has a deleterious effect on observed latency.
How does this compare to non-virtualized 10gig ethernet though?
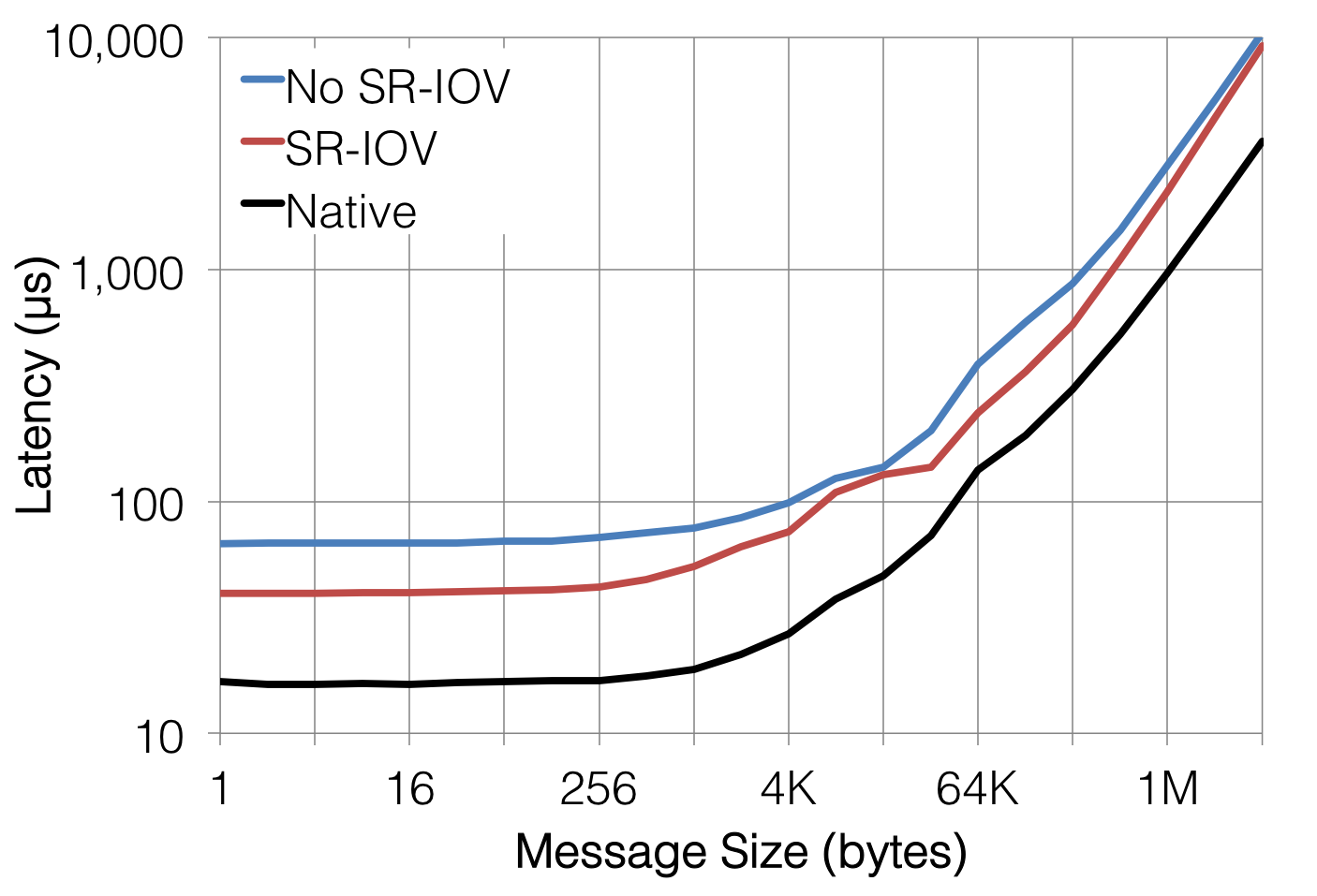
As it turns out, 40% better than "terrible" is still "not very good." Amazon's new C3 instances with SR-IOV still demonstrate between 2× and 2.5× more latency than non-virtualized 10gig. Interestingly, this performance gap is significantly smaller when comparing SR-IOV'ed InfiniBand and non-virtualized InfiniBand. The nature of TCP/IP and Ethernet is such that SR-IOV really isn't shifting virtualization from low-performance to high-performance in terms of message passing latency; it's just making a bad idea a little more palatable.
Bandwidth
Technologically, SR-IOV's biggest benefit is in improving latency, but the latency data above also showed SR-IOV outperforming non-SR-IOV even for very large messages. This suggests that bandwidth is somehow benefiting. Is it?
 |
| MPI bandwidth. Note the semilog axes. |
No. The benefit of SR-IOV over non-SR-IOV virtualization is much less apparent when measuring bandwidth, which is to be expected. As was discovered the last time I benchmarked Amazon EC2's cluster compute instances, Amazon continues to under-deliver bandwidth by a significant margin. Messaging bandwidth never surpasses 500 MB/s, which is around 40% of line speed. By comparison, the non-virtualized 10gig cluster delivered between 1.5× and 2.0× the measurable bandwidth. I should also note that the non-virtualized 10gig was operating under less-than-ideal circumstances: my nodes were sharing switches with other jobs, and I'm not entirely sure what the topology connecting my four nodes was.
Bidirectional Bandwidth
For the sake of completeness in comparing these new C3 instances to the previous cc2 instances, I also measured the bidirectional bandwidth.
 |
| MPI bidirectional bandwidth |
Just like the cc2 instances, both SR-IOV and non-SR-IOV C3 instances realize only a small fraction of their bidirectional bandwidth. For intermediate-sized messages, data seems to flow at full duplex rates, but the bandwidth-limiting regime shows performance on par with unidirectional message passing. This suggests that whatever background network congestion exists underneath the VMs in EC2 renders the networking performance of Amazon's cluster compute instances very sensitive to bandwidth-heavy communication patterns regardless of if SR-IOV is used or not. In a practical sense, this means that algorithms such as multidimensional fast Fourier transforms (FFTs), which are bisection-bandwidth-limited, will perform terribly on EC2. The application benchmarks I presented at SC'13 highlighted this.
Unfortunately, comparing these new C3 instances featuring SR-IOV to non-virtualized 10gig reminds us that the overall network performance of Amazon EC2 is pretty terrible. Although there is a 40% drop in latency, EC2's C3 instances display over 2× the latency of non-virtualized 10gig. Worse yet, there is only minimal improvement in the bandwidth available to C3 instances over these SR-IOV-virtualized 10gig connections. Cluster compute instances are still only able to achieve around 40% of the theoretical peak bandwidth, and congestion caused by full-duplex communication and all-to-all message passing severely degrades the overall performance.
Thus, even with SR-IOV, trying to run tightly coupled parallel problems on Amazon EC2's new C3 instances is still not a great idea. Applications that demand a lot of bandwidth will be hitting a weak spot in the EC2 infrastructure. For workloads that are latency-limited, though, there's no reason not to use the new SR-IOV-enabled C3 instances. The performance increase should be noticeable over the previous generation of Amazon's cluster compute, but the virtualization overheads still remain extremely high.
At a Glance
Amazon's use of SR-IOV to virtualize the 10gig connections between its new C3 does have significant measurable performance improvements over the last generation's virtualized I/O in terms of latency. The jitter in the latency is also substantially reduced, and this "Enhanced Networking" with SR-IOV does represent a big step forward in increasing the performance of EC2's cluster compute capabilities.Unfortunately, comparing these new C3 instances featuring SR-IOV to non-virtualized 10gig reminds us that the overall network performance of Amazon EC2 is pretty terrible. Although there is a 40% drop in latency, EC2's C3 instances display over 2× the latency of non-virtualized 10gig. Worse yet, there is only minimal improvement in the bandwidth available to C3 instances over these SR-IOV-virtualized 10gig connections. Cluster compute instances are still only able to achieve around 40% of the theoretical peak bandwidth, and congestion caused by full-duplex communication and all-to-all message passing severely degrades the overall performance.
Thus, even with SR-IOV, trying to run tightly coupled parallel problems on Amazon EC2's new C3 instances is still not a great idea. Applications that demand a lot of bandwidth will be hitting a weak spot in the EC2 infrastructure. For workloads that are latency-limited, though, there's no reason not to use the new SR-IOV-enabled C3 instances. The performance increase should be noticeable over the previous generation of Amazon's cluster compute, but the virtualization overheads still remain extremely high.