SC'24 recap
The premiere annual conference of the high-performance computing community, SC24, was held in Atlanta last week, and it attracted a record-shattering number of attendees--nearly 18,000 registrants, up 28% from last year! The conference felt big as well, and there seemed to be a lot more running between sessions, meetings, and the exhibition floor. Despite its objectively bigger size though, the content of the conference felt more diffuse this year, and I was left wondering if this reflected my own biases or was a real effect of the AI industry beginning to overflow into AI-adjacent technology conferences like SC.

Of course, this isn't to say that SC24 was anything short of a great conference. Some exciting new technologies were announced, a new supercomputer beat out Frontier to become the fastest supercomputer on the Top500 list, and I got to catch up with a bunch of great people that I only get to see at shows like this. I'll touch on all of these things below. But this year felt different from previous SC conferences to me, and I'll try to talk about that too.
There's no great way to arrange all the things I jotted down in my notes, but I've tried to arrange them by what readers may be interested in. Here's the table of contents:
- My approach to SC this year
- New technology and announcements
- The HPC industry overall
- Community and connections
- So what's the takeaway?
Before getting into the details though, I should explain how my perspective shaped what I noticed (and missed) through the conference. And to be clear: these are my own personal opinions and do not necessarily reflect those of my employer. Although Microsoft covered the cost for me to attend SC, I wrote this blog post during my own free time over the Thanksgiving holiday, and nobody had any editorial control over what follows except me.
My approach to SC this year
Although this is the eleventh SC conference I've attended, it was the first time that I:
- attended as a practitioner of hyperscale AI rather than traditional HPC and scientific computing
- attended as a Microsoft engineer (I represented Microsoft as a product manager at SC22 and SC23)
- did not attend SC as a designated storage person (since 2013)
Because of these changes in my identity as an attendee, I approached the conference with a different set of goals in mind:
As a hyperscale/AI person, I felt that I should prioritize attending all the cloud and AI sessions whenever forced to choose between one session or another. I chose to focus on understanding the traditional HPC community's understanding of hyperscale and AI, which meant I had to spend less time in the workshops, panels and BOFs where I built my career.
As an engineer rather than a product manager, it wasn't my primary responsibility to run private briefings and gather HPC customers' requirements and feedback. Instead, I prioritized only those meetings where my first-hand knowledge of how massive-scale AI training works could have a meaningful impact. This meant I focused on partners and practitioners who also operate in the realm of hyperscale--think massive, AI-adjacent companies and the HPC centers who have historically dominated the very top of the Top500 list.
One thing I didn't anticipate going into SC24 is that I've inherited a third identity: there are a new cohort of people in HPC who see me as a long-time community member. This resulted in a surprising amount of my time being spent talking to students and early career practitioners who were looking for advice.
These three identities and goals meant I don't many notes to share on the technical program, but I did capture more observations about broader trends in the HPC industry and community.
New technology and announcements
Top500 and a new #1 system
A cornerstone of every SC conference is the release of the new Top500 list on Monday, and this is especially true on years when a new #1 supercomputer is announced. As was widely anticipated in the weeks leading up to SC24, El Capitan unseated Frontier as the new #1 supercomputer this year, posting an impressive 1.74 EFLOPS of FP64. In addition though, Frontier grew a little (it added 400 nodes), there was a notable new #5 system (Eni's HPC6), and a number of smaller systems appeared that are worth calling out.
#1 - El Capitan
The highlight of the Top500 list was undoubtedly the debut of El Capitan, Lawrence Livermore National Laboratory's massive new MI300A-based exascale supercomputer. Its 1.74 EF score resulted from a 105-minute HPL run that came in under 30 MW, and a bunch of technical details about the system were disclosed by Livermore Computing's CTO, Bronis de Supinski, during an invited talk during the Top500 BOF. Plenty of others summarize the system's speeds and feeds (e.g., see The Next Platform's article on El Cap), so I won't do that. However, I will comment on how unusual Bronis' talk was.
Foremost, the El Capitan talk seemed haphazard and last-minute. Considering the system took over half a decade of planning and cost at least half a billion dollars, El Capitan's unveiling was the most unenthusiastic description of a brand-new #1 supercomputer I've ever seen. I can understand that the Livermore folks have debuted plenty of novel #1 systems in their careers, but El Capitan is objectively a fascinating system, and running a full-system job for nearly two hours across first-of-a-kind APUs is an amazing feat. If community leaders don't get excited about their own groundbreaking achievements, what kind of message should the next generation of HPC professionals take home?
In sharp contrast to the blasé announcement of this new system was the leading slide that was presented to describe the speeds and feeds of El Capitan:

I've never seen a speaker take the main stage and put a photo of himself literally in the center of the slide, in front of the supercomputer they're talking about. I don't know what the communications people at Livermore were trying to do with this graphic, but I don't think it was intended to be evocative of the first thing that came to my mind:

The supercomputer is literally named "The Captain," and there's a photo of one dude (the boss of Livermore Computing, who is also standing on stage giving the talk) blocking the view of the machine. It wasn't a great look, and it left me feeling very uneasy about what I was witnessing and what message it was sending to the HPC community.
In case it needs to be said, HPC is a team sport. The unveiling of El Capitan (or any other #1 system before it) is always the product of dozens, if not hundreds, of people devoting years of their professional lives to ensuring it all comes together. It was a big miss, both to those who put in the work, and those who will have to put in the work on future systems, to suggest that a single, smiling face represents the success of the system deployment.
#5 - Eni HPC6
The other notable entrant to the Top 10 list was HPC6, an industry system deployed by Eni (a major Italian energy company) built on MI250X. Oil and gas companies tend to be conservative in the systems they buy since the seismic imaging done on their large supercomputers informs hundred-million to billion-dollar investments in drilling a new well, and they have much less tolerance for weird architectures than federally funded leadership computing does. Thus, Eni's adoption of AMD GPUs in this #5 system is a strong endorsement of their capability in mission-critical commercial computing.
#16 and #17 - SoftBank CHIE-2 and CHIE-3
SoftBank, the Japanese investment conglomerate who, among other things, owns a significant stake in Arm, made its Top500 debut with two identical 256-node DGX H100 SuperPODs. While not technologically interesting (H100 is getting old), these systems represent significant investment in HPC by private industry in Japan and signals that SoftBank is following the lead of large American investment groups in building private AI clusters for the AI startups in their portfolios. In doing this, SoftBank's investments aren't dependent on third-party cloud providers to supply the GPUs to make these startups successful and reduces their overall risk.
Although I didn't hear anything about these SoftBank systems at the conference, NVIDIA issued a press statement during the NVIDIA AI Summit Japan during the week prior to SC24 that discussed SoftBank's investment in large NVIDIA supercomputers. The press statement states that these systems will be used "for [SoftBank's] own generative AI development and AI-related business, as well as that of universities, research institutions and businesses throughout Japan." The release also suggests we can expect B200 and GB200 SuperPODs from SoftBank to appear as those technologies come online.
#18 - Jülich's JUPITER Exascale Transition Instrument (JETI)
Just below the SoftBank systems was the precursor system to Europe's first exascale system. I was hoping that JUPITER, the full exascale system being deployed at FZJ, would appear in the Top 10, but it seems like we'll have to wait for ISC25 for that. Still, the JETI system ran HPL across 480 nodes of BullSequana XH3000, the same node that will be used in JUPITER, and achieved 83 PFLOPS. By comparison, the full JUPITER system will be over 10x larger ("roughly 6000 compute nodes" in the Booster), and projecting the JETI run (173 TF/node) out to this full JUPITER scale indicates that JUPITER should just squeak over the 1.0 EFLOPS line.
In preparation for JUPITER, Eviden had a couple of these BullSequana XH3000 nodes out on display this year:

And if you're interested in more, I've been tracking the technical details of JUPITER in my digital garden.
#32 - Reindeer!
Waay down the list was Microsoft's sole new Top500 entry this cycle, an NVIDIA H200 system that ran HPL over 120 ND H200 v5 nodes in Azure. It was one of only two conventional (non-Grace) H200 clusters that appeared in the top 100, and it had a pretty good efficiency (Rmax/Rpeak > 80%). Microsoft also had a Reindeer node on display at its booth:

An astute observer may note that this node looks an awful lot like the H100 node used in its Eagle supercomputer, which was on display at SC23 last year. That's because it's the same chassis, just with an upgraded HGX baseboard.
Reindeer was not super exciting, and there were no press releases about it, but I mention it here for a couple reasons:
- One of my teammates did the HPL run and submission, and his group got to come up with the name of the system for the purposes of HPL. As it turns out, generating a public name for a Top500 submission involves a comical amount of legal and marketing process when it comes from a giant corporation like Microsoft. And as it turns out, naming a cluster "Reindeer" has a low probability of offending anyone.
- Reindeer is pretty boring--it's a relatively small cluster with a bunch of GPUs. But when you're building out AI infrastructure at a pace of 5x Eagles (70,000 GPUs!) per month, you want the clusters that those GPUs go into to be as boring, predictable, and automatable as possible. Seeing as how Reindeer only used 960 GPUs but still got #32, it doesn't require much math to realize that the big hyperscalers could flood the Top500 list with these cookie-cutter GPU clusters and (in this case) make any ranking below #32 completely irrelevant. Heaven help the Top500 list if they ever publish an API for submitting new systems; cloud providers' build validation automation could tack a Top500 submission on at the end of burn-in and permanently ruin the list.
Technology on the exhibit floor
The exhibit floor had a few new pieces of HPC technology on display this year that are worthy of mention, but a lot of the most HPC-centric exciting stuff actually had a soft debut at ISC24 in May. For example, even though SC24 was MI300A's big splash due to the El Capitan announcement, some MI300A nodes (such as the Cray EX255a) were on display in Hamburg. However, Eviden had their MI300A node (branded XH3406-3) on display at SC24 which was new to me:

I'm unaware of anyone who's actually committed to a large Eviden MI300A system, so I was surprised to see that Eviden already has a full blade design. But as with Eni's HPC6 supercomputer, perhaps this is a sign that AMD's GPUs (and now APUs) have graduated from being built-to-order science experiments to a technology ecosystem that people will want to buy off the rack.
There was also a ton of GH200 on the exhibit hall floor, but again, these node types were also on display at ISC24. This wasn't a surprise since a bunch of upcoming European systems have invested in GH200 already; in addition to JUPITER's 6,000 GH200 nodes described above, CSCS Alps has 2,688 GH200 nodes, and Bristol's Isambard-AI will have 1,362 GH200 nodes. All of these systems will have a 1:1 CPU:GPU ratio and an NVL4 domain, suggesting this is the optimal way to configure GH200 for HPC workloads. I didn't hear a single mention of GH200 NVL32.
GB200
SC24 was the debut of NVIDIA's Blackwell GPU in the flesh, and a bunch of integrators had material on GB200 out at their booths. Interestingly, they all followed the same pattern as GH200 with an NVL4 domain size, and just about every smaller HPC integrator followed a similar pattern where
- their booth had a standard "NVIDIA Partner" (or "Preferred Partner!") placard on their main desk
- they had a bare NVIDIA GB200 baseboard (superchip) on display
- there wasn't much other differentiation
From this, I gather that not many companies have manufactured GB200 nodes yet, or if they have, there aren't enough GB200 boards available to waste them on display models. So, we had to settle for these bare NVIDIA-manufactured, 4-GPU + 2-CPU superchip boards:

What struck me is that these are very large FRUs--if a single component (CPU, GPU, voltage regulator, DRAM chip, or anything else) goes bad, you have to yank and replace four GPUs and two CPUs. And because all the components are soldered down, someone's going to have to do a lot of work to remanufacture these boards to avoid throwing out a lot of very expensive, fully functional Blackwell GPUs.
There were a few companies who were further along their GB200 journey and had more integrated nodes on display. The HPE Cray booth had this GB200 NVL4 blade (the Cray EX154n) on display:

It looks remarkably sparse compared to the super-dense blades that normally slot into the Cray EX line, but even with a single NVL4 node per blade, the Cray EX cabinet only supports 56 of these blades, leaving 8 blade slots empty in the optimal configuration. I assume this is a limitation of power and cooling.
The booth collateral around this blade suggested its use case is "machine learning and sovereign AI" rather than traditional HPC, and that makes sense since each node has 768 GB of HBM3e which is enough to support training some pretty large sovereign models. However, the choice to force all I/O traffic on to the high-speed network by only leaving room for one piddly node-local NVMe drive (this blade only supports one SSD per blade) will make training on this platform very sensitive to the quality of the global storage subsystem. This is great if you bundle this blade with all-flash Lustre (like Cray ClusterStor) or DAOS (handy, since Intel divested the entire DAOS development team to HPE). But it's not how I would build an AI-optimized system.
I suspect the cost-per-FLOP of this Cray GB200 solution is much lower than what a pure-play GB200 for LLM training would be. And since GB200 is actually a solid platform for FP64 (thanks to Dan Ernst for challenging me on this and sharing some great resources on the topic), I expect to see this node do well in situations that are not training frontier LLMs, but rather fine-tuning LLMs, training smaller models, and mixing in traditional scientific computing on the same general-purpose HPC/AI system.
Speaking of pure-play LLM training platforms, though, I was glad that very few exhibitors were trying to talk up GB200 NVL72 this year. It may have been the case that vendors simply aren't ready to begin selling NVL72 yet, but I like to be optimistic and instead believe that the exhibitors who show up to SC24 know that the scientific computing community likely won't get enough value out of a 72-GPU coherence domain to justify the additional cost and complexity of NVL72. I didn't see a single vendor with a GB200 NVL36 or NVL72 rack on display (or a GH200 NVL32, for that matter), and not having to think about NVL72 for the week of SC24 was a nice break from my day job.
Perhaps the closest SC24 got to NVL72 was a joint announcement at the beginning of the week by Dell and CoreWeave, who announced that they have begun bringing GB200 NVL72 racks online. Dell did have a massive, AI-focused booth on the exhibit floor, and they did talk up their high-powered, liquid-cooled rack infrastructure. But in addition to supporting GB200 with NVLink Switches, I'm sure that rack infrastructure would be equally good at supporting nodes geared more squarely at traditional HPC.
Slingshot 400
HPE Cray also debuted a new 400G Slingshot switch, appropriately named Slingshot 400. I didn't get a chance to ask anyone any questions about it, but from the marketing material that came out right before the conference, it sounds like a serdes upgrade without any significant changes to Slingshot's L2 protocol.
There was a Slingshot 400 switch for the Cray EX rack on display at their booth, and it looked pretty amazing:

It looks way more dense than the original 200G Rosetta switch, and it introduces liquid-cooled optics. If you look closely, you can also see a ton of flyover cables connecting the switch ASIC in the center to the transceivers near the top; similar flyover cables are showing up in all manner of ultra-high-performance networking equipment, likely reflecting the inability to maintain signal integrity across PCB traces.
The port density on Slingshot 400 remains the same as it was on 200G Slingshot, so there's still only 64 ports per switch, and the fabric scale limits don't increase. In addition, the media is saying that Slingshot 400 (and the GB200 blade that will launch with it) won't start appearing until "Fall 2025." Considering 64-port 800G switches (like NVIDIA's SN5600 and Arista's 7060X6) will have already been on the market by then though, Slingshot 400 will be launching with HPE Cray on its back foot.
However, there was a curious statement on the placard accompanying this Slingshot 400 switch:

It reads, "Ultra Ethernet is the future, HPE Slingshot delivers today!"
Does this suggest that Slingshot 400 is just a stopgap until 800G Ultra Ethernet NICs begin appearing? If so, I look forward to seeing HPE Cray jam third-party 800G switch ASICs into the Cray EX liquid-cooled form factor at future SC conferences.
Grace-Grace for storage?
One of the weirder things I saw on the exhibit floor was a scale-out storage server built on NVIDIA Grace CPUs that the good folks at WEKA had on display at their booth.

Manufactured by Supermicro, this "ARS-121L-NE316R" server (really rolls off the tongue) uses a two-socket Grace superchip and its LPDDR5X instead of conventional, socketed CPUs and DDR. The rest of it seems like a normal scale-out storage server, with sixteen E3.S SSD slots in the front and four 400G ConnectX-7 or BlueField-3 NICs in the back. No fancy dual-controller failover or anything like that; the presumption is that whatever storage system you'd install over this server would implement its own erasure coding across drives and servers.
At a glance, this might seem like a neat idea for a compute-intensive storage system like WEKA or DAOS. However, one thing that you typically want in a storage server is high reliability and repairability, features which weren't the optimal design point for these Grace superchips. Specifically,
- The Grace-Grace superchip turn both CPU sockets into a single FRU. This means that if one CPU goes bad, you're shipping the whole board back to NVIDIA rather than just doing a field-swap of a socket.
- Grace uses LPDDR5X, whose ECC is not as robust as DDR5. I'm not an expert on memory architecture, but my understanding is that the ECC scheme on Grace does not provide ChipKill or row failures. And as with CPU failure, if a single DRAM chip goes back, you're throwing out two CPUs and all the DRAM.
- There's no way to value-engineer the exact quantity of cores, clock, and DRAM to be optimal for the storage software installed on top of these servers.
On the upside, though, there might be a cost advantage to using this Grace-Grace server over a beefier AMD- or Intel-based server with a bunch of traditional DIMMs. And if you really like NVIDIA products, this lets you do NVIDIA storage servers to go with your NVIDIA network and NVIDIA compute. As long as your storage software can work with the interrupt rates of such a server (e.g., it supports rebuild-on-read) and the 144 Neoverse V2 cores are a good fit for its computational requirements (e.g., calculating complex erasure codes), this server makes sense. But building a parallel storage system on LPDDR5X still gives me the willies.
I could also see this thing being useful for certain analytics workloads, especially those which may be upstream of LLM training. I look forward to hearing about where this turns up in the field.
Microsoft and AMD's new HBM CPU
The last bit of new and exciting HPC technology that I noted came from my very own employer in the form of HBv5, a new, monster four-socket node featuring custom-designed AMD CPUs with HBM. STH wrote up an article with great photos of HBv5 and its speeds and feeds, but in brief, this single node has:
- 384 physical Zen 4 cores (352 accessible from within the VM) that clock up to 4 GHz
- 512 GB of HBM3 (up to 450 GB accessible from the VM) with up to 6.9 TB/s STREAM bandwidth
- 4x NDR InfiniBand NICs clocked at 200G per port
- 200G Azure Boost NIC (160G accessible from the VM)
- 8x 1.84 TB NVMe SSDs with up to 50 GB/s read and 30 GB/s write bandwidth
The node itself looks kind of wacky as well, because there just isn't a lot on it:

There are the obvious four sockets of AMD EPYC 9V64H, each with 96 physical cores and 128 GB of HBM3, and giant heat pipes on top of them since it's 100% air-cooled. But there's no DDR at all, no power converter board (the node is powered by a DC bus bar), and just a few flyover cables to connect the PCIe add-in-card cages. There is a separate fan board with just two pairs of power cables connecting to the motherboard, and that's really about it.
The front end of the node shows its I/O capabilities which are similarly uncomplicated:

There are four NDR InfiniBand cards (one localized to each socket) which are 400G-capable but cabled up at 200G, eight E1.S NVMe drives, and a brand-new dual-port Azure Boost 200G NIC. Here's a close-up of the right third of the node's front:

This is the first time I've seen an Azure Boost NIC in a server, and it looks much better integrated than the previous-generation 100G Azure SmartNIC that put the FPGA and hard NIC on separate boards connected by a funny little pigtail. This older 100G SmartNIC with pigtail was also on display at the Microsoft booth in an ND MI300X v5 node:

And finally, although I am no expert in this new node, I did hang around the people who are all week, and I repeatedly heard them answer the same few questions:
- Is this MI300C? It is if you want it to be. You can call it Sally if you want; I don't think it will care. But Microsoft calls it HBv5, and the processor name will show up as AMD EPYC 9V64H in /proc/cpuinfo.
- Is its InfiniBand 1x800 port, 2x400 ports, ...? There are four NDR InfiniBand HCA cards, and each card has one full 400G NDR InfiniBand port. However, each port is only connected up to top-of-rack switching at 200G. Each InfiniBand HCA hangs off of a different EPYC 9V64H socket so that any memory address can get to InfiniBand without having to traverse Infinity Fabric. Running four ports of NDR InfiniBand at half speed is an unusual configuration, but that's what's going on here.
- How can I buy this CPU? EPYC 9V64H are "custom AMD EPYC processors only available in Azure." This means the only way to access it is by provisioning an HBv5 virtual machine in Azure.
The HPC industry overall
New technology announcements are always exciting, but one of the main reasons I attend SC and ISC is to figure out the broader trends shaping the HPC industry. What concerns are top of mind for the community, and what blind spots remain open across all the conversations happening during the week? Answering these questions requires more than just walking the exhibit floor; it involves interpreting the subtext of the discussions happening at panels and BOF sessions. However, identifying where the industry needs more information or a clearer picture informs a lot of the public-facing talks and activities in which I participate throughout the year.
What I learned about the average SC technical program attendee
The biggest realization that I confirmed this week is that the SC conference is not an HPC conference; it is a scientific computing conference. I sat in a few sessions where the phrase "HPC workflows" was clearly a stand-in for "scientific workflows," and "performance evaluation" still really means "MPI and OpenMP profiling." I found myself listening to ideas or hearing about tools that were intellectually interesting but ultimately not useful to me because they were so entrenched in the traditions of applying HPC to scientific computing. Let's talk about a few ways in which this manifested.
People think sustainability and energy efficiency are the same thing
Take, for example, the topic of sustainability. There were talks, panels, papers, and BOFs that touched on the environmental impact of HPC throughout the week, but the vast majority of them really weren't talking about sustainability at all; they were talking about energy efficiency. These talks often use the following narrative:
- Energy use from datacenters is predicted to reach some ridiculous number by 2030
- We must create more energy-efficient algorithms, processors, and scheduling policies
- Here is an idea we tested that reduced the energy consumption without impacting the performance of some application or workflow
- Sustainability achieved! Success!
The problem with this approach is that it declares victory when energy consumption is reduced. This is a great result if all you care about is spending less money on electricity for your supercomputer, but it completely misses the much greater issue that the electricity required to power an HPC job is often generated by burning fossil fuels, and that the carbon emissions that are directly attributable to HPC workloads are contributing to global climate change. This blind spot was exemplified by this slide, presented during a talk titled "Towards Sustainable Post-Exascale Leadership Computing" at the Sustainable Supercomputing workshop:

I've written about this before and I'll write about it again: FLOPS/Watt and PUE are not meaningful metrics by themselves when talking about sustainability. A PUE of 1.01 is not helpful if the datacenter that achieves it relies on burning coal for its power. Conversely, a PUE of 1.5 is not bad if all that electricity comes from a zero-carbon energy source. The biggest issue that I saw being reinforced at SC this year is that claims of "sustainable HPC" are accompanied by the subtext of "as long as I can keep doing everything else the way I always have."
There were glimmers of hope, though. Maciej Cytowski from Pawsey presented the opening talk at the Sustainable Supercomputing workshop, and he led with the right thing--he acknowledged that 60% of the fuel mix that powers Pawsey's supercomputers comes from burning fossil fuels:
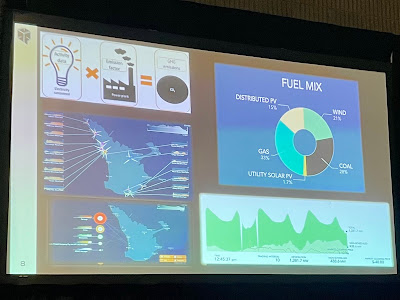
Rather than patting himself on the back at his low PUE, Dr. Cytowski's described on how they built their datacenter atop a large aquifer from which they draw water at 21°C and return it at 30°C to avoid using energy-intensive chillers. To further reduce the carbon impact of this water loop, Pawsey also installed over 200 kW of solar panels on its facility roof to power the water pumps. Given the fact that Pawsey cannot relocate to somewhere with a higher ratio of zero-carbon energy on account of its need to be physically near the Square Kilometer Array, Cytowski's talk felt like the most substantive discussion on sustainability in HPC that week.
Most other talks and panels on the topic really wanted to equate "sustainability" to "FLOPS per Watt" and pretend like where one deploys a supercomputer is not a part of the sustainability discussion. The reality is that, if the HPC industry wanted to take sustainability seriously, it would talk less about watts and more about tons of CO2. Seeing as how the average watt of electricity in Tennessee produces 2.75x more carbon than a watt of electricity in Washington, the actual environmental impact of fine-tuning Slurm scheduling or fiddling with CPU frequencies is meaningless when compared to the benefits that would be gained by deploying that supercomputer next to a hydroelectric dam instead of a coal-fired power plant.
I say all this because there are parts of the HPC industry (namely, the part in which I work) who are serious about sustainability. And those conversations go beyond simply building supercomputers in places where energy is low-carbon (thereby reducing Scope 2 emissions). They include holding suppliers to high standards on reducing the carbon impact of transporting people and material to these data centers, reducing the carbon impact of all the excess packaging that accompanies components, and being accountable for the impact of everything in the data center after it reaches end of life (termed Scope 3 emissions).
The HPC community--or more precisely, the scientific computing community--is still married to the idea that the location of a supercomputer is non-negotiable, and "sustainability" is a nice-to-have secondary goal. I was hoping that the sessions I attended on sustainability would approach this topic at a level where the non-scientific HPC world has been living. Unfortunately, the discussion at SC24, which spanned workshops, BOFs, and Green 500, remains largely stuck on the idea that PUE and FLOPS/Watt are the end-all sustainability metrics. Those metrics are important, but there are global optimizations that have much greater effects on reducing the environmental impact of the HPC industry.
AI sessions are really scientific computing sessions about AI
Another area where "HPC" was revealed to really mean "scientific computing" was in the topic of AI. I sat in on a few BOFs and panels around AI topics to get a feel for where this community is in adopting AI for science, but again, I found the level of discourse to degrade to generic AI banter despite the best efforts of panelists and moderators. For example, I sat in the "Foundational Large Language Models for High-Performance Computing" BOF session, and Jeff Vetter very clearly defined what a "foundational large language model" was at the outset so we could have a productive discussion about their applicability in HPC (or, really, scientific computing):

The panelists did a good job of outlining their positions. On the upside, LLMs are good for performing source code conversion, documenting and validating code, and maximizing continuity in application codes that get passed around as graduate students come and go. On the downside, they have a difficult time creating efficient parallel code, and they struggle to debug parallel code. And that's probably where the BOF should have stopped, because LLMs, as defined at the outset of the session, don't actually have a ton of applicability in scientific computing. But as soon as the session opened up to audience questions, the session went off the rails.
The first question was an extremely basic and nonspecific question: "Is AI a bubble?"
It's fun to ask provocative questions to a panel of experts. I get it. But the question had nothing to do with LLMs, any of the position statements presented by panelists, or even HPC or scientific computing. It turned a BOF on "LLMs for HPC" into a BOF that might as well have been titled "Let's just talk about AI!" A few panelists tried to get things back on track by talking about the successes of surrogate models to simulate physical processes, but this reduced the conversation to a point where "LLMs" really meant "any AI model" and "HPC" really meant "scientific simulations."
Perhaps the most productive statement to come out of that panel was when Rio Yokota asserted that "we" (the scientific community) should not train their own LLMs, because doing so would be "unproductive for science." But I, as well as anyone who understands the difference between LLMs and "AI," already knew that. And the people who don't understand the difference between an LLM and a surrogate model probably didn't pick up on Dr. Yokota's statement, so I suspect the meaning of his contribution was completely lost.
Walking out of that BOF (and, frankly, the other AI-themed BOFs and panels I attended), I was disappointed at how superficial the conversation was. This isn't to say these AI sessions were objectively bad; rather, I think it reflects the general state of understanding of AI amongst SC attendees. Or perhaps it reflects the demographic that is drawn to these sorts of sessions. If the SC community is not ready to have a meaningful discussion about AI in the context of HPC or scientific computing, attending BOFs with like-minded peers is probably a good place to begin getting immersed.
But what became clear to me this past week is that SC BOFs and panels with "AI" in their title aren't really meant for practitioners of AI. They're meant for scientific computing people who are beginning to dabble in AI.
AI for operations is not yet real in scientific computing
I was invited to sit on a BOF panel called "Artificial Intelligence and Machine Learning for HPC Workload Analysis" following on a successful BOF in which I participated at ISC24. The broad intent was to have a discussion around the tools, methods, and neat ideas that HPC practitioners have been using to better understand workloads, and each of us panelists was tasked with talking about a project or idea we had in applying AI/ML to improve some aspect of workloads.

What emerged from us speakers' lightning talks is that applying AI for operations--in this case, understanding user workloads--is nascent. Rather than talking about how we use AI to affect how we design or operate supercomputers, all of us seemed to focus more on how we are collecting data and beginning to analyze that data using ML techniques. And maybe that's OK, because AI won't ever do anything for workload characterization until you have a solid grasp of the telemetry you can capture about those workloads in the first place.
But when we opened the BOF up to discussion with all attendees, despite having a packed room, there was very little that the audience had. Our BOF lead, Kadidia Konaté, tried to pull discussion out of the room from a couple of different fronts by asking what tools people were using, what challenges they were facing, and things along those lines. However, it seemed to me that the majority of the audience was in that room as spectators; they didn't know where to start applying AI towards understanding the operations of supercomputers. Folks attended to find out the art of the possible, not talk about their own challenges.
As such, the conversation wound up bubbling back up to the safety of traditional topics in scientific computing--how is LDMS working out, how do you deal with data storage challenges of collecting telemetry, and all the usual things that monitoring and telemetry folks worry about. It's easy to talk about the topics you understand, and just as the LLM conversation reverted back to generic AI for science and the sustainability topic reverted back to FLOPS/Watt, this topic of AI for operations reverted back to standard telemetry collection.
Some are beginning to realize that HPC exists outside of scientific computing
Despite the pervasive belief at SC24 that "HPC" and "scientific computing" are the same thing, there are early signs that the leaders in the community are coming to terms with the reality that there is now a significant amount of leadership HPC happening outside the scope of the conference. This was most prominent at the part of the Top500 BOF where Erich Strohmaier typically discusses trends based on the latest publication of the list.
In years past, Dr. Strohmaier's talk was full of statements that strongly implied that, if a supercomputer is not listed on Top500, it simply does not exist. This year was different though: he acknowledged that El Capitan, Frontier, and Aurora were "the three exascale systems we are aware of," now being clear that there is room for exascale systems to exist that simply never ran HPL, or never submitted HPL results to Top500. He explicitly acknowledged again that China has stopped making any Top500 submissions, and although he didn't name them outright, he spent a few minutes dancing around "hyperscalers" who have been deploying exascale class systems such as Meta's H100 clusters (2x24K H100), xAI's Colossus (100K H100), and the full system behind Microsoft's Eagle (14K H100 is a "tiny fraction").
Strohmaier did an interesting analysis that estimated the total power of the Top500 list's supercomputers so he could compare it to industry buzz around hyperscalers building gigawatt-sized datacenters:

It was a fun analysis where he concluded that there are between 500-600 megawatts of supercomputers on the Top500 list, and after you factor in storage, PUE, and other ancillary power sources, the whole Top500 list sums up to what hyperscalers are talking about sticking into a single datacenter facility.
Although he didn't say it outright, I think the implication here is that the Top500 list is rapidly losing relevance in the broad HPC market, because a significant amount of the world's supercomputing capacity and capability are absent from the list. Although specific hyperscale supercomputers (like Meta's, xAI's, and Microsoft's) were not mentioned outright, their absence from the Top500 list suggests that this list might already be more incomplete than it is complete--the sum of the FLOPS or power on the Top500 supercomputers may be less than the sum of the giant supercomputers which are known but not listed. This will only get worse as the AI giants keep building systems every year while the government is stuck on its 3-5 year procurement cycles.
It follows that the meaning of the Top500 is sprinting towards a place where it is not representative of HPC so much as it is representative of the slice of HPC that serves scientific computing. Erich Strohmaier was clearly aware of this in his talk this year, and I look forward to seeing how the conversation around the Top500 list continues to morph as the years go on.
NSF's broad front vs. DOE's big bets in HPC and AI
My career was started at an NSF HPC center and built up over my years in the DOE, so I feel like I owe a debt to the people who provided all the opportunities and mentorship that let me get to the place of privilege in the hyperscale/AI industry that I now enjoy. As a result, I find myself still spending a lot of my free time thinking about the role of governments in the changing face of HPC (as evidenced by my critiques of thinktank reports and federal RFIs...) and trying to bridge the gap in technical understanding between my old colleagues (in DOE, NSF, and European HPC organizations) and whatever they call what I work on now (hyperscale AI?).
To that end, I found myself doing quite a bit of business development (more on this later) with government types since I think that is where I can offer the most impact. I used to be government, and I closely follow the state of their thinking in HPC, but I also know what's going on inside the hyperscale and AI world. I also have enough context in both areas to draw a line through all the buzzy AI press releases to demonstrate how the momentum of private-sector investment in AI might affect the way national HPC efforts do business. So, I did a lot of talking to both my old colleagues in DOE and their industry partners in an attempt to help them understand how the hyperscale and AI industry thinks about infrastructure, and what they should expect in the next year.
More importantly though, I also sat in on a couple of NSF-themed BOFs to get a better understanding of where their thinking is, where NAIRR is going, how the NSF's strategy contrasts with DOE's strategy, and where the ambitions of the Office of Advanced Cyberinfrastructure might intersect with the trajectory of hyperscale AI.
What I learned was that NSF leadership is aware of everything that the community should be concerned about: the growth of data, the increasing need for specialized silicon, the incursion of AI into scientific computing, new business models and relationships with industry, and broadening the reach of HPC investments to be globally competitive. But beyond that, I struggled to see a cohesive vision for the future of NSF-funded supercomputing.
A BOF with a broad range of stakeholders probably isn't the best place to lay out a vision for the future of NSF's HPC efforts, and perhaps NSF's vision is best expressed through its funding opportunities and awards. Whichever the case may be, it seems like the NSF remains on a path to make incremental progress on a broad front of topics. Its Advanced Computing Systems and Services (ACSS) program will continue to fund the acquisition of newer supercomputers, and a smorgasbord of other research programs will continue funding efforts across public access to open science, cybersecurity, sustainable software, and other areas. My biggest concern is that peanut-buttering funding across such a broad portfolio will make net forward progress much slower than taking big bets. Perhaps big bets just aren't in the NSF's mission though.
NAIRR was also a topic that came up in every NSF-themed session I attended, but again, I didn't get a clear picture of the future. Most of the discussion that I heard was around socializing the resources that are available today through NAIRR, suggesting that the pilot's biggest issue is not a lack of HPC resources donated by industry, but awareness that NAIRR is a resource that researchers can use. This was reinforced by a survey whose results were presented in the NAIRR BOF:

It seems like the biggest challenges facing the NSF community relying on NAIRR (which has its own sample bias) is that they don't really know where to start even though they have AI resources (both GPUs and model API services) at their disposal. In a sense, this is a great position for the NSF since
- its users need intellectual help more than access to GPU resources, and the NSF has been great at promoting education, training, and workforce development.
- its users are unlikely to demand the same cutting-edge GPUs that AI industry leaders are snapping up. For example, the largest pool of GPUs in NAIRR are A100 GPUs that NVIDIA donated via DGX Cloud; the big AI companies moved off of Ampere a year ago and are about to move off of Hopper.
However, it also means that there's not a clear role for partnership with many industry players beyond donating resources to the NAIRR pilot today in the hopes of selling resources to the full NAIRR tomorrow. I asked what OAC leadership thought about moving beyond such a transactional relationship between NSF and industry at one of the BOFs I attended, and while the panelists were eager to explore specific answers to that question, I didn't hear any ideas that would approach some sort of truly equitable partnership where both parties contributed in-kind.
I also walked away from these NSF sessions struck by how different the NSF HPC community's culture is from that of the DOE. NSF BOF attendees seemed focused on getting answers and guidance from NSF leadership, unlike the typical DOE gathering, where discussions often revolve around attendees trying to shape priorities to align with their own agendas. A room full of DOE people tends to feel like everyone thinks they're the smartest person there, while NSF gatherings appear more diverse in the expertise and areas of depth of its constituents. Neither way is inherently better or worse, but it will make the full ambition of NAIRR (as an inter-agency collaboration) challenging to navigate. This is particularly relevant as DOE is now pursuing its own multi-billion-dollar AI infrastructure effort, FASST, that appears to sidestep NAIRR.
Exhibitor trends
There's no better way to figure out what's going on in the HPC industry than walking the exhibit floor each year, because booths cost money and reflect the priorities (and budgets) of all participants. This year's exhibit felt physically huge, and walking from one end to the other was an adventure. You can get a sense of the scale from this photo I took during the opening gala:

Despite having almost 18,000 registrants and the opening gala usually being a crush of people, the gala this year felt and looked very sparse just because people and booths were more spread out. There was also a perceptibly larger number of splashy vendors who have historically never attended before who were promoting downstream HPC technologies like data center cooling and electrical distribution, and there was healthy speculation online about whether the hugeness of the exhibit this year was due to these new power and cooling companies.
To put these questions to rest, I figured out how to yank down all the exhibitor metadata from the conference website so I could do some basic analysis on it.
Booths by the numbers
The easiest way to find the biggest companies to appear this year was to compare the exhibitor list and booth sizes from SC23 to this year and see whose booth went from zero to some big square footage.

I only took the top twenty new vendors, but they broadly fall into a couple of categories:
- Power and cooling: Stulz, Delta, Airedale, Valvoline, Boundary Electric, Schneider Electric, Mara
- Server manufacturing: Wistron, AMI, Pegatron
- Higher ed: Tennessee Tech, SCRCC
There were a couple other companies that must've just missed last SC but aren't new to the show (NetApp, Ansys, Samsung, Micron, Broadcom). And curiously, only one new GPU-as-a-Service provider (Nebius) showed up this year, suggesting last year was the year of the GPU Cloud.
But to confirm what others had speculated: yes, a significant amount of the new square footage of the exhibit floor can be attributed to companies focused on power and cooling. This is an interesting indicator that HPC is becoming mainstream, largely thanks to AI demanding ultra-high density of power and cooling. But it's also heartening to see a few new exhibitors in higher education making an appearance. Notably, SCRCC (South Carolina Research Computing Consortium) is a consortium between Clemon, University of South Carolina, and Savannah River National Laboratory that just formed last year, and I look forward to seeing what their combined forces can bring to bear.
We can also take a look at whose booths grew the most compared to SC23:

This distribution is much more interesting, since the top 20 exhibitors who grew their footprint comprise the majority of the growth in existing exhibitors. Cherry-picking a few interesting growers:
- Power and cooling: USystems, Midas, Vertiv
- Data center/GPUaaS: iM, Iris Energy, and (arguably) Oracle
- Software: Arc Compute and CIQ
- Companies facing serious financial or legal troubles: I count at least three! Impressive that they are still pouring money into their SC booths.
It's also interesting to see HLRS, the German national HPC center, grow so significantly. I'm not sure what prompted such a great expansion, but I take it to mean that things have been going well there.
Finally, Dell had a massive booth and showing this year. Not only did they grow the most since SC23, but they had the single largest booth on the exhibit floor at SC24. This was no doubt a result of their great successes in partnering with NVIDIA to land massive GPU buildout deals at places like xAI and CoreWeave. They also had "AI factory" messaging emblazoned all over their marketing material and debuted a nice 200 kW liquid-cooled rack that will be the basis for their GB200 NVL72 solution, clearly leaning into the idea that they are leaders in AI infrastructure. Despite this messaging being off-beat for the SC audience as I've described earlier, their booth was surprisingly full all the time, and I didn't actually get a chance to get in there to talk to anyone about what they've been doing.
Equally interesting are the vendors who reduced their footprint at SC24 relative to SC23:
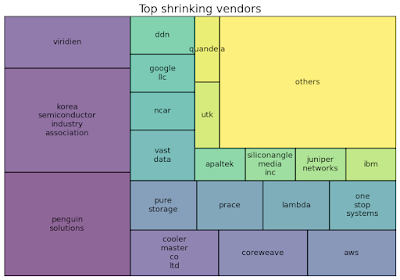
Reading too much into any of these big shrinkers is pretty easy; while a reduction in booth size could suggest business hasn't been as good, it could equally mean that an exhibitor just went overboard at SC23 and downsized to correct this year. A few noteworthy exhibitors to call out:
- Penguin and the Korea Semiconductor Industry Association both cut way back from massive 50x50 booths to 30x30. Their booths this year were both big, but they weren't massive. Viridien, formerly known as CGG, also shrunk from a massive booth to a less-massive 30x40.
- Juniper still kept an independent booth, but it is in the process of being absorbed into HPE. Shrinking makes sense.
- Major cloud providers Google and AWS scaled back, but Microsoft did not.
- GPU-as-a-Service cloud providers CoreWeave and Lambda both scaled back. Since these GPUaaS providers' business models typically rely on courting few big customers, it may make sense to cut back on booth volume.
- Major AI storage companies DDN, VAST, and (to a lesser degree) Pure also scaled back, while WEKA did not. I know business for DDN and VAST has been great this past year, so these may just reflect having gone overboard last year.
Overall, almost twice as many vendors grew their booths than scaled back, so I'd caution anyone against trying to interpret any of this as anything beyond exhibitors right-sizing their booths after going all-in last year.
Finally, there are a handful of vendors who disappeared outright after SC23:

It is critical to point out that the largest booths to vanish outright were all on the smaller size: SUSE, Tenstorrent, and Symbiosys Alliance all disappeared this year, but their booths last year were only 20x30. I was surprised to see that Tenstorrent and Arm didn't have booths, but the others are either companies I haven't heard of (suggesting the return on investment of showing at SC might've been low), are easy to rationalize as only being HPC-adjacent (such as SNIA and DigitalOcean), or simply went bankrupt in the last year.
As we say at the business factory, the net-net of the exhibit hall this year is that the square footage of booth space increased by 15,000 square feet, so it was in fact bigger, it did take longer to walk from one end to the other, and there definitely were a bunch of new power and cooling companies filling out the space. Some exhibitors shrank or vanished, but the industry as a whole appears to be moving in a healthy direction.
And if you're interested in analyzing this data more yourself, please have a look at the data and the Jupyter notebook I used to generate the above treemaps on GitHub. If you discover anything interesting, please write about it and post it online!
Proliferation of GPU-as-a-Service providers
As an AI infrastructure person working for a major cloud provider, I kept an eye out for all the companies trying to get into the GPU-as-a-Service game. I described these players last year as "pure-play GPU clouds," and it seems like the number of options available to customers who want to go this route is growing. But I found it telling that a lot of them had booths that were completely indistinguishable from each other. Here's an example of one:

As best I can tell, these companies are all NVIDIA preferred partners with data centers and a willingness to deploy NVIDIA GPUs, NVIDIA SmartNICs, and NVIDIA cloud stack, and sell multi-year commitments to consume those GPUs. I tried to accost some of these companies' booth staff to ask them my favorite question ("What makes you different from everyone else?"), but most of these companies' booths were staffed by people more interested in talking to each other than me.
These GPUaaS providers tend to freak me out, because, as Microsoft's CEO recently stated, these companies are often "just a bunch of tech companies still using VC money to buy a bunch of GPUs." I can't help but feel like this is where the AI hype will come back to bite companies who have chosen to build houses upon sand. Walking the SC24 exhibit floor is admittedly a very narrow view of this line of business, but it seemed like some of these companies were content to buy up huge booths, hang a pretty banner above it, and otherwise leave the booth empty of anything beyond a few chairs and some generic value propositions. I didn't feel a lot of hunger or enthusiasm from these companies despite the fact that a bunch of them have hundreds of millions of dollars of GPUs effectively sitting on credit cards that they are going to have to make payments on for the next five years.
That all said, not all the companies in the GPUaaS are kicking back and letting the money pour in. In particular, I spent a few minutes chatting up someone at the CoreWeave booth, and I was surprised to hear about how much innovation they're adding on top of their conventional GPUaaS offering. For example, they developed Slurm on Kubernetes (SUNK) with one of their key customers to close the gap between the fact that CoreWeave exposes its GPU service through Kubernetes, but many AI customers have built their stack around Slurm, pyxis, and enroot.
In a weird twist of fate, I later ran into an old acquaintance who turned out to be one of the key CoreWeave customers for whom SUNK was developed. He commented that SUNK is the real deal and does exactly what his users need which, given the high standards that this person has historically had, is a strong affirmation that SUNK is more than just toy software that was developed and thrown on to GitHub for an easy press release. CoreWeave is also developing some interesting high-performance object storage caching software, and all of these software services are provided at no cost above whatever customers are already paying for their GPU service.
I bring this up because it highlights an emerging distinction in the GPUaaS market, which used to be a homogenous sea of bitcoin-turned-AI providers. Of course, many companies still rely on that simple business model: holding the bill for rapidly depreciating GPUs that NVIDIA sells and AI startups consume. However, there are now GPUaaS providers moving up the value chain by taking on the automation and engineering challenges that model developers don't want to deal with. Investing in uncertain projects like new software or diverse technology stacks is certainly risky, especially since they may never result in enough revenue to pay for themselves. But having a strong point of view, taking a stance, and investing in projects that you feel are right deserves recognition. My hat is off to the GPUaaS providers who are willing to take these risks and raise the tide for all of us rather than simply sling NVIDIA GPUs to anyone with a bag of money.
Community and connections
As much as I enjoy increasing shareholder value, the part of SC that gives me the greatest joy is reconnecting with the HPC community. Knowing I'll get to chat with my favorite people in the industry (and meet some new favorite people!) makes the long plane rides, upper respiratory infections, and weird hotel rooms completely worth it.

I wound up averaging under six hours of sleep per night this year in large part because 9pm or 7am were often the only free times I had to meet with people I really wanted to see. I have this unhealthy mindset where every hour of every day, from the day I land to the day I leave, is too precious to waste, and it's far too easy for me to rationalize that spending an hour talking to someone interesting is worth losing an hour of sleep.
But like I said at the outset of this blog post, this year felt different for a few reasons, and a lot of them revolve around the fact that I think I'm getting old. Now, it's always fun to say "I'm getting old" in a mostly braggadocious way, but this feeling manifested in concrete ways that affected the way I experienced the conference:
- I hit my limit on Monday night and couldn't get home without spending 15 minutes sitting in an unlit playground across from the World of Coke. I've always gotten blisters and fatigue, but this was the first time I couldn't just cowboy up and muscle through it. To avoid a repeat of this, I wound up "wasting" (see above) a lot more time to just get off my feet this year.
- This year, I reached the point where I need to start time-box how much time I spend chatting up the folks I bump into. I used to just let the good times roll if I ran into someone I knew, but this year I wound up spending as much time attending sessions as I did missing sessions because I got caught up in a conversation. This isn't a bad thing per se, but I did feel a little sour when I realized I'd made a bad bet on choosing to chat instead of attending a session or vice versa, and this bad feeling lingered in the back of my mind just about every day.
- There weren't a lot of surprises for me at the conference this year, and I worry that I am at risk of losing touch with the technical aspects of the conference that get newer attendees excited. Instead of hearing about, say, the latest research in interconnects, more of my time was spent mucking it up with the sorts of people in the HPC community who I used to find intimidating. On the one hand, hooray me for making it into old boys' clubs. But on the other, I don't want to become some HPC greybeard whose last meaningful contribution to the industry was twenty years ago.
- This is the first year where I've had people accost me and ask me for advice. I've long been accosted by strangers because of my online presence, but those interactions were always lighthearted exchanges of "I follow you on Twitter" and "Great to meet you. Have an @HPC_Guru pin." This year, I had people specifically ask me for advice on industry versus postdoc, AI versus HPC, and what my master plan was when I left NERSC. Even though I didn't have any sage advice, I still found it really hard to tell bright-eyed students to go kick rocks just so I wouldn't be late for yet another mushy panel on AI.
If you read this all and think "boo hoo, poor Glenn is too popular and wise for his own good," yeah, I get it. There are worse problems to have. But this was the first year where I felt like what I put into the conference was greater than what I got out of it. Presenting at SC used to be at least as good for my career as it was useful for my audiences, but it just doesn't count for much given my current role and career stage. It felt like some of the magic was gone this year in a way I've never experienced before.
Getting to know people
As the years have gone on, I spend an increasing amount of my week having one-on-one conversations instead of wandering aimlessly. This year though, I came to SC without really having anything to buy or sell:
- I am not a researcher, so I don't need to pump up the work I'm doing to impress my fellow researchers.
- I no longer own a product market segment, so I don't directly influence the customers or vendors with whom my employer works.
- I don't have any bandwidth in my day job to support any new customers or partnerships, so I don't have a strong reason to sell people on partnering with me or my employer.
Much to my surprise though, a bunch of my old vendor/partner colleagues still wanted to get together to chat this year. Reflecting back, I was surprised to realize that it was these conversations--not the ones about business--that were the most fulfilling this year.
I learned about people's hobbies, families, and their philosophies on life, and it was amazing to get to know some of the people behind the companies with whom I've long dealt. I was reminded that the person is rarely the same as the company, and even behind some of the most aggressive and blusterous tech companies are often normal people with the same concerns and moments of self-doubt that everyone else has. I was also reminded that good engineers appreciate good engineering regardless of whether it's coming from a competitor or not. The public persona of a tech exec may not openly admire a competitor's product, but that doesn't mean they don't know good work when they see it.
I also surprised a colleague whose career has been in the DOE labs with an anecdote that amounted to the following: even though two companies may be in fierce competition, the people who work for them don't have to be. The HPC community is small enough that almost everyone has got a pal at a competing company, and when there are deals to be made, people looove to gossip. If one salesperson hears a juicy rumor about a prospective customer, odds are that everyone else on the market will hear about it pretty quickly too. Of course, the boundaries of confidentiality and professionalism are respected when it matters, but the interpersonal relationships that are formed between coworkers and friends don't suddenly disappear when people change jobs.
And so, I guess it would make sense that people still want to talk to me even though I have nothing to buy or sell. I love trading gossip just as much as everyone else, and I really enjoyed this aspect of the week.
Talking to early career people
I also spent an atypically significant amount of my week talking to early career people in HPC who knew of me one way or another and wanted career advice. This is the first year I recall having the same career conversations with multiple people, and this new phase of my life was perhaps most apparent during the IEEE TCHPC/TCPP HPCSC career panel in which I was invited to speak this year.

It was an honor to be asked to present on a career panel, but I didn't feel very qualified to give career advice to up-and-coming computer science graduate students who want to pursue HPC. I am neither a computer scientist nor a researcher, but fortunately for me, my distinguished co-panelists (Drs. Dewi Yokelson, Olga Pearce, YJ Ji, Rabab Alomairy, and Florina Ciorba) had plenty of more relevant wisdom to share. And at the end of the panel, there were a few things we all seemed to agree on as good advice:
- Knowing stuff is good, but being able to learn things is better. Being eager to learn and naturally curious makes this much easier as well.
- The life of a researcher sometimes requires more than working a standard nine-to-five, so it'll be hard to be really successful if your heart isn't in it.
- People will forget what you did or what you said, but they remember how you made them feel. Don't be a jerk, because this community is small.
In both this panel the one-on-one conversations I had with early career individuals, the best I could offer was the truth: I never had a master plan that got me to where I am; I just try out new things until I realize I don't like doing them anymore. I never knew what I wanted to be when I grew up, and I still don't really, so it now makes me nervous that people have started approaching me with the assumption that I've got it all figured out. Unless I torpedo my career and go live on a goat farm though, maybe I should prepare for this to be a significant part of my SC experiences going forward.
Shift in social media
One last, big change in the community aspect of SC this year was the mass-migration of a ton of HPC folks from Twitter to Bluesky during the week prior to the conference. I don't really understand what prompted it so suddenly; a few of us have been trying for years to get some kind of momentum on other social platforms like Mastodon, but the general lack of engagement meant that all the excitement around SC always wound up exclusively on Twitter. This year was different though, and Bluesky hit critical mass with the HPC community.
I personally have never experienced an SC conference without Twitter; my first SC was in 2013, and part of what made that first conference so exciting was being able to pull up my phone and see what other people were seeing, thinking, and doing across the entire convention center via Twitter. Having the social media component to the conference made me feel like I was a part of something that first year, and as the years went on, Twitter became an increasingly indispensable part of the complete SC experience for me.
This year, though, I decided to try an experiment and see what SC would be like if I set Twitter aside and invested my time into Bluesky instead.
The verdict? It was actually pretty nice.
It felt a lot like the SC13 days, where my day ended and began with me popping open Bluesky to see what new #SC24 posts were made. And because many of the tech companies and HPC centers hadn't yet made it over, the hashtag wasn't clogged up by a bunch of prescheduled marketing blasts that buried the posts written by regular old conference attendees who were asking important questions:
Which booths at #sc24 have coffee? I noticed oracle do. Anyone else?
— Mike Croucher (@walkingrandomly.bsky.social) November 18, 2024 at 3:02 PM
Of course, I still clogged Bluesky up with my nonsense during the week, but there was an amazing amount of engagement by a diversity of thoughtful people--many who came from Twitter, but some whose names and handles I didn't recognize.
The volume of traffic on Bluesky during the week did feel a little lower than what it had been on Twitter in years past though. I also didn't see as many live posts of technical sessions as they happened, so I couldn't really tell whether I was missing something interesting in real time. This may have contributed to why I felt a little less connected to the pulse of the conference this year than I had in the past. It also could've been the fact that conference was physically smeared out across a massive space though; the sparsity of the convention center was at least on par with the sparsity on Bluesky.
At the end of the week, I didn't regret the experiment. In fact, I'll probably be putting more effort into my Bluesky account than my Twitter account going forward. To be clear though, this isn't a particularly political decision on my part, and I pass no judgment on anyone who wants to use one platform over the other. It's just that I like the way I feel when I scroll through my Bluesky feeds, and I don't get that same feeling when I use Twitter.
So what's the takeaway?
SC this year was a great conference by almost every measure, as it always is, but it still felt a little different for me. I'm sure that some of that feeling is the result of my own growth, and my role with respect to the conference seems to be evolving from someone who gets a lot out of the conference to someone who is giving more to the conference. That's not to say that I don't get a lot out of it, though; I had no shortage of wonderful interactions with everyone from technology executives to rising stars who are early in their career, and I learned a lot about both them and me as whole people. But SC24, more than any SC before it, is when I realized this change was happening.
On the technological front, we saw the debut of a new #1 system (emblazoned with the smiling face of Bronis...) and a growing crop of massive, new clusters deployed for commercial applications. The exhibit floor was quantitatively bigger, in large part due to new power and cooling companies who are suddenly relevant to the HPC world thanks to the momentum of AI. At the same time, the SC technical program is clearly separating itself out as a conference focused on scientific computing; the level of discourse around AI remains largely superficial compared to true AI conferences, the role of hyperscalers in the HPC industry is still cast more as a threat than an opportunity.
For my part, I'm still trying to get a grasp on where government agencies like DOE and NSF want to take their AI ambitions so I can try to help build a better mutual understanding between the scientific computing community and the hyperscale AI community. However, it seems like the NSF is progressing slowly on a wide front, while the DOE is doing what DOE does and charging headfirst into a landscape that has changed more than I think they realize.
There's a lot of technical content that I know I missed on account of the increasing time I've been spending on the people and community aspect of the conference, and I'm coming to terms with the idea that this just may be the way SC is from now on. And I think I'm okay with that, since the support of the community is what helped me go from being a bored materials science student into someone whose HPC career advice is worth soliciting in the short span of eleven years. Despite any or all of the cynicism that may come out in the things I say about this conference, SC is always the highlight of my year. I always go into it with excitement, gladly burn the candle at both ends all week, and fly home feeling both grateful for and humbled by everything the HPC community has done and continues to do to keep getting me out of bed in the morning.